[ Hadoop ] 하둡이란 무엇인가? 하둡 에코시스템(Core Hadoop Ecosystem)
in BackEnd
하둡에 대해 알아보기 전에, 하둡 에코시스템을 알아보면 하둡을 이해할때 도움이 됩니다.
에코시스템이란 중앙시스템(여기서는 하둡)의 활용성을 더 높이기 위해 이것저것 소프트웨어가 추가된 시스템을 가지고 에코시스템이라고 하는데요,
이런 에코시스템을 활용함으로서 하둡의 생산성을 높일수 있기 때문에 하둡은 하둡을 중심으로 하는 많은 에코시스템을 가지고 있습니다. 아래의 사진은 하둡에코시스템을 그려놓은 그림이라고 할 수 있겠네요=)
아래글은 udemy 하둡강좌를 수강하면서 복습+번역 한 글입니다.
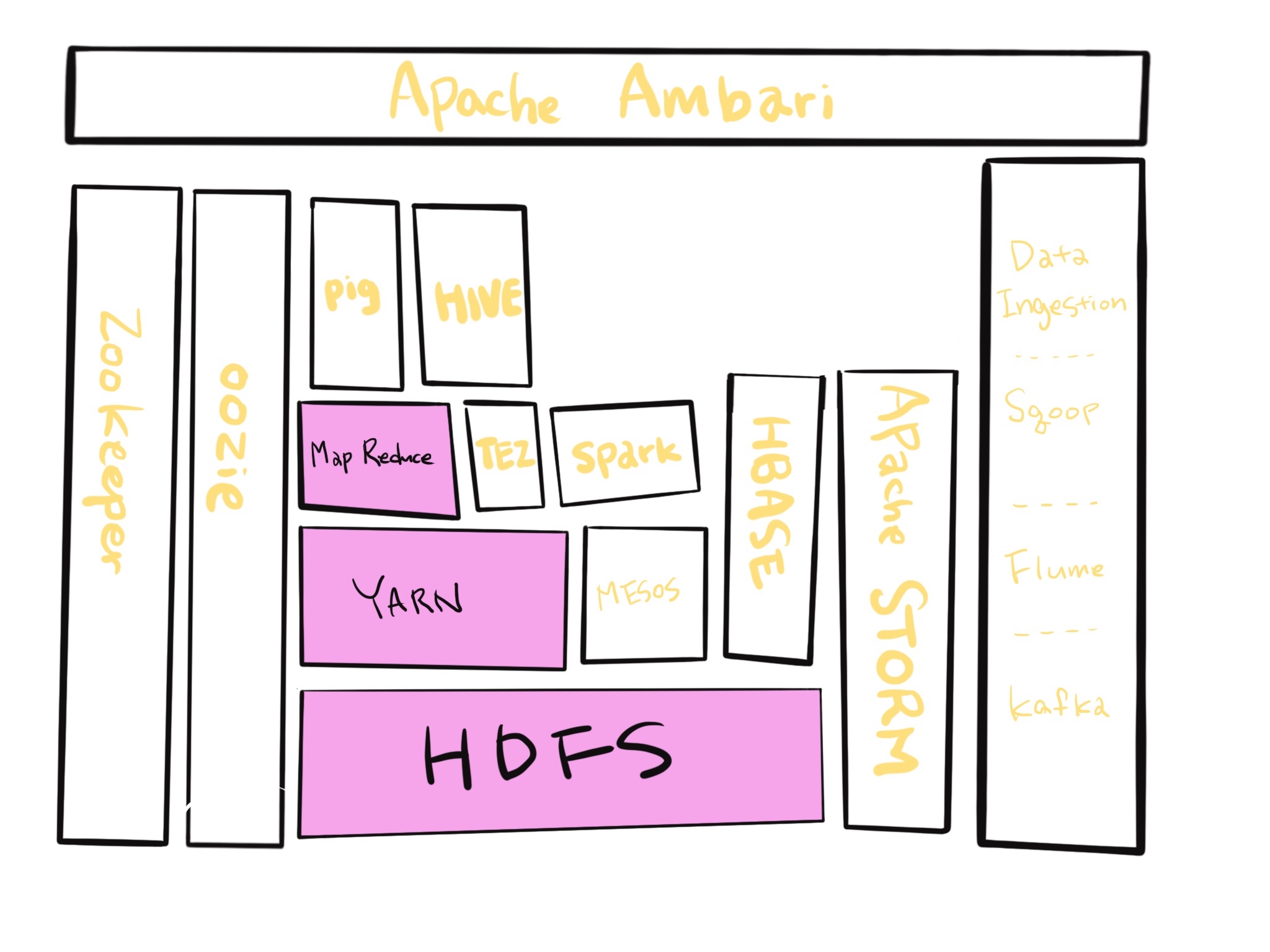
HDFS : HDFS는 클러스터(여러 대의 컴퓨터들이 연결되어 하나의 시스템처럼 동작하는 컴퓨터들의 집합)를 오가는 빅데이터를 보관소에 분배함으로써, 내 클러스터에 있는 모든 하드 드라이브를 거대한 하나의 파일 시스템으로 보여줍니다.
이 뿐만 아니라 HDFS는 많은 양의 데이터의 복사본을 만들어서 파일을 유지할 수 있도록 도와줍니다.
그래서 만약, 난데없이 컴퓨터 하나가 불길에 사로잡혀서 녹아내렸다고 칩시다(실제로 일어난대요ㅋㅋㅋ). 그러면 이 HDFS는 타버린 내용을 복구시키고 자동으로 자신의 복사본을 백업해버립니다. 마치 아무일도 없었다는 듯이요… 이게 HDFS의 가장 큰 핵심입니다.
YARN: YARN(Yet Another Resource Megotiator)은 데이터 가공이 시작되고 본격적으로 데이터를 가지고 노는 것이라고 생각할 수 있습니다. YARN은 기본적으로 컴퓨팅클러스터의 리소스를 관리하는 시스템이라고 보면 되는데요.
YARN은 추가적인 업무를 위해 어떤 노드들이 지금 구동가능 혹은 구동불가능한지 판단해서 임무를 수행할지를 결정합니다. 뭐, 클러스터가 계속해서 굴러갈수있도록 지속지켜주는 심장박동이라고 생각할수도 있겠네요. 우리에게 주어진 이 자원negotiator을 이용해서 흥미로운 어플리케이션들을 위에 쌓아볼 수 있겠습니다 =)
MapReduce : Mappers have the ability to transform your data in parallel across your entire computing cluster in a very efficient manner. And reducers are what aggregate that data together and it may sound like a very simple model and it it, but it’s actually very versatile and we’ll see later on that there are some very creative ways you can put mappers and reducers together to solve very complex problems. Now originally map reduce and YARN were kind of the same thing in Hadoop. They got split out recently and that’s enabled other applications to be built on top of yarn that solve the same problem as map reduce but in a more efficient manner.
YARN위에 쌓을 수 있는 흥미로운 어플리케이션등 중 하나는 map reduce인데요, 이것은 mappers와 reducers로 구성되어있습니다. 이 둘은 당신이 map reduce프로그램을 사용할때 다른 functions를 작성할 수 있는 다른 스크립트입니다.
Mappers는 굉장히 효율적인 방법으로 전체 컴퓨터 클러스터에서 데이터를 동일방향으로 변형할 수 있는 능력을 가지고 있고, Reducers는 모아진 데이터를 집합한 것인데, 이것들은 들리기에는 매우 간단한 모델이라고 생각 될 수 있습니다. 하지만 사실 이것은 매우 다방면으로 이루어져있고, 나중에 다루겠지만 이 mappers와 reducers를 모두 사용하여 창의적인 방법으로 매우 복잡한 문제들을 해결할 수 있습니다. 현재 map reduce와 YARN은 hadoop내에서 거의 동일한것으로 치부되어집니다. 이 두가지는 최근에 분리되었고, 이 둘이 분리됨에 따라 다른 어플리케이션들이 map reduce와 같은 문제들을 더욱 효과적인 방법으로 해결하며 yarn위에 지어질 수 있게 되었습니다.
Pig : If you dont’ want to write Java or oython map reduce code and you’re more familiar with a scripting language that has sort of a SQL style syntax, Pig is for you so Pig is a very high level programming API that allows you to write simple scripts that look a lot like SQL in some cases that allow you to chain together queries and get complex answers but without actually writing Python or Java code in the process, so pig will actually transform that script into something that will run on map reduce which in turn goes through yarn and HDFS to actually process and get the data that it needs to get the answer you want. That’s pig. Just a high level scripting language that sits on top of map reduce.
HIVE : Talk about hive next which also sits on top of map reduce and it solves a similar problem to pig but it really more directly looks like a SQL database so hive is a way of actually taking SQL queries and making this distributed data that’s just really sitting on your file system somewhere look like a SQL database. So for all intents and purposes it’s just like a database. You can even connect to it through a shell client or ODBC or what have you. And actually execute SQL queries on the data that’s stored on your Hadoop cluster even though it’s not really a relational database under the hood. So if you’re familiar with SQL Hive might be a very useful API - useful interface for you to use.
Ambari : We’ll talk next about Ambari and Apache Ambari is basically this thing that sits on top of everything and it just gives you a view of your cluster and lets you visualize what’s running on your cluster Whatsystems are using how much resources and also has some views in it that allow you to actually do things like execute hive queries or import databases into hive or execute Pig queries and things like that. So Ambari is what sits on top of all this and lets you have a view into the actual state of your clusterand the applications that are running on it. Now there are other technologies that do this for you and Ambari is what Hortonworks uses.There are competing distributions of Hadoop stacks out there, Hortonworks being one of them. Other ones include Cloudera and MapR but for Hortonworks they use Anbari.
MESOS : Mesos so Mesos isn’t really part of Hadoop proper but I’m including it here because it’s basically an alternative to yarn. So it too is a resource negotiator remember YARN is yet another resource negotiator Mesos is another one they basically solve the same problems in different ways there are of course pros and cons to using each one that we’ll talk about later on. But Mesos is another potential way of managing the resources on your cluster. And there are ways of getting Mesos and YARN to work together if you need to as well. And we bring up mesos because we’re gonna talk about Spark which I think is one of the most exciting technologies in the Hadoop ecosystem this is sitting at the same level of map reduce in that it sits on top of yarn or Mesos it can go either way to actually run queries on your data and like MapReduce it requires some programming and need to actually write your SPARK scripts using either Python or Java or the Scala programming language Scala being preferred.
SPARK : But SPARK is kind of where it’s at right now it is extremely fast it’s under a lot of active development right now so Spark’s a very exciting technology right now and a very powerful technology. So if you need to very quickly and efficiently and reliably process data on your cluster SPARK is areally good choice for that. And it’s also very versatile it can do things like handle SQL queries that can do machine learning across an entire cluster of information. It can actually handle streaming data in real time and all sorts of other cool stuff.
TEZ : Moving on Tez similar to spark in that it also uses some of the same techniques as SPARK notably with something that’s called a directed acyclic graph and this gives Tez a leg up on what map reduce does because it can produce more optimal plans for actually executing queries. Tez is usually used in conjunction with Hive to accelerate it. So we remember we looked at hive earlier that kind of sat on top of map reduce but it can also sit on op of Tez. So you have an option there high through Tez can often be faster than high through map reduce. Both different means of optimizing queries to get a efficient answer from your cluster.
HBASE : So HBase kind of sits off to the side and it’s a way of exposing the data on your cluster to transactional platforms so HBase is what we call a NoSQL database. It is a columnar data store and you might have heard that term before it’s basically a really really fast database meant for very large transaction rates so it’s appropriate for example for hitting froma web application hitting from a Web site doing all types of transactions so HBase can actually expose the data that’s stored on your cluster and maybe that data was transformed in some way by spark or mapreduce or something else. And it provides a very fast way of exposing those results to other systems.
Apache STORM : Storm is basically a way of processing streaming data. So if you have streaming data from say sensors or web logs you can actually process that in real time using storm and spark streaming solves the same problem. Storm just does it in a slightly different way. So Apache storm’s made for processing streaming data quickly in real time so it doesn’t have to be a batch thing anymore. You can actually update your machine learning models or transform data into a database all in real time as it comes in.
OOZIE : Let’s go over here to Oozie. Oozie is just a way of scheduling jobs on your cluster. So if you have a task that needs to happen on your Hadoop cluster that involves many different stepsand maybe many different systems. Oozie’s a way of scheduling all of these things together into jobs that can be run on some sort of schedule. So when you have more complicated operations that require loading data into hive and then integrating that with Pig and maybe querying it with SPARK and then transforming the results into HBase Oozie can manage that all for you and make sure that it runs reliably on a consistent basis.
ZooKeeper : Moving over here a bit zookeeper also sits alongside all of these technologies. It’s basically a technology for coordinating everything on your cluster. So it’s it’s the technology that can be used for keeping track of which nodes are up which nodes are down. It’s a very reliable way of just kind of keeping track of shared states across your cluster thatdifferent applications can use and many many of these applications we’ve talked about rely on zookeeperto actually maintain reliable and consistent performance across the cluster.Even when a node randomly goes down. So zookeeper can be used for example for keeping track of who the current master node is or keepingtrack of who’s up who’s down what have you. And it’s really more more extensible than that even.
Data ingestion : Over here there’s also systems that are just focused on the problem of data ingestion. So how do we actually get data into your cluster and onto HDFS from external sources.
Sqoop : Sqoop for example is a way of actually tying your Hadoop database into a relational database. Anything that can talk to ODBC or JDBC can be transformed by Sqoop into your HDFS file system so Sqoop is basically a connector between Hadoop and your legacy databases.
Flume : It’s a way of actually transporting Web logs at a very large scale and very reliably to your cluster. So let’s say you have a fleet of web servers Flume can actually listen to the web logs coming in from those web servers in real time and publish them into your cluster in real time for processing by something like storm or spark streaming.
Kafka : Kafka solves a similar problem although it’s a little bit more general purpose. It can basically collect data of any sort from a cluster of PCs from a cluster of web servers or whatever it is and broadcast that into your Hadoop cluster as well. So those are all three technologies that solve the problem of data ingestion.
