[ Problem Solving 회고 ] 프록시 우회 크롤러 제작기
4개월을 고민했던 프록시 우회용 크롤러제작을 마쳤다.
왜 만들었는지, 어떤 문제를 마주쳤는지, 어떻게 해결했는지, 그래서 어떤 결과를 얻었는지에 대해서 회고를 해보려한다.
사실 회사에서는 아무도 나에게 이정도 난이도의 퀘스트를 준적이 없다. (시키지도 않았다)
그냥 나의 오기가 그걸 그냥 넘기지 않았다는게 문제…
그럼 어떤 과정을 겪었는지 기록해봐야겠다.
현재 상황
크롤러를 제작하는게 나의 현재의 메인업무다.
물론 크롤링을 정식으로 배우지는 않았지만, 지금까지 만들어온 크롤러의 갯수나 로직을 봐서는
이제는 어지간한 크롤러든 만들수있겠다는 대강의 로직은 가지고 있었다.

크롤러를 하나씩 만들면서 ‘다음 크롤러는 뭘 만들까?’ 라고 늘 생각해온 나였기에 (파워J)
기본적인 난이도의 크롤러를 전부 만든뒤에, 이제 막 ‘다음은 뭘 만들까’라는 고민을 하고 있을 찰나였다.
회사에서 일을 하다보면 회사가 지금 가지고 있는 문제를 알게 된다.
문제의 시작
문제는, (회사에서도 꽤 오랜기간 해결하려했지만 해결하지 못한 문제중 1번째 문제였다)
내 ip가 타겟 페이지 서버에 자주 요청을 하니까, 서버 부하가 걸린다는 이유로 내 ip를 차단한것이다
그리고 진짜 혹시나해서 다시 말하지만, 공공기관의 크롤링은 ‘공공기관의 정보공개에 관한 법률‘이라고 법에 명시되어있을만큼 국민의 알권리를 위해 공개를 해야하는게 맞다. 그러므로 ‘부하가 걸린다’느니 같은 말도 안되는 핑계는 그냥 자기네들 귀찮아서 차단하는거다
그래서 처음에는, 전화를 했다. (사실 가끔은 이렇게 개발이 아닌 방향의 문제해결이 더 직접적일때가 있다)
‘입찰정보회사인데 xx한 이유로 크롤링을 했는데 간격 넓게해서 크롤링할테니 ip 풀어달라’고.
그래서 내 ip를 풀어줬다. 나는 당연히 크롤링하는 전보다는 훨씬 간격을 띄워서 크롤링을 했다.
근데 새로운 문제는 그 다음에 발생했다. 내 아이피로 접속하니까 정보가 이상한 정보를 가져오는거다.
예를들어 이런식이었다.
1,2페이지의 정보는 제대로 가져오는데, 3페이지부터는 한번에 불러와야할 데이터가 10개라면 7개,8개만 크롤링이 되거나,
아니면 중복데이터가 있거나, 10페이지가 넘어가면 아예 데이터가 없는 식이었다.
(이것도 테스트해본게, 처음 던져보는 아이피로 크롤링하니까 처음부터 끝까지 제대로 가지고 왔다.)
분명 내 아이피를 어디다 등록해놓고, 내가 크롤링을 시도하면 다른 정보를 던지는것 같았다.
그래서 생각했다.
이건.. 크롤링여부를 떠나서 내 ip로 접근하면 무조건 못하겠다. 그렇다고 매번 새 컴퓨터를 살수는 없고..
매번 크롤링할때마다 내 ip가 아닌 ip를 사용할수는 없는건가? 그런방법이 있긴한가?
라는 고민으로 해결방안을 찾기 시작했다.
해결의 시작
이때를 되돌아 생각해보면, 어떻게 검색을 해야하는지도 몰랐던것 같다.
프록시가 뭔지도 잘 몰랐어서 처음에는 개념을 검색하는것도 참 막연했다.
근데 정말 하루종일 이 문제에 대해 검색을 하다보니 (영어로 검색했다), 블로그에 올라와있는 글 중에 ‘내가 이 책을 썼는데 크롤링에 대해 더 깊게 알고 싶다면 구매 추천!’
이라는 식의 배너를 보게되었고, 목차를 보니 완전히 내가 원했던 내용이라 망설이지 않고 바로 전자책을 구매했다.
특히 자바로 크롤링을 하는 경우가 많지 않았어서 더 그랬다. 이때쯤의 열풍은 파이썬으로 크롤링하는것이었다.
그리고 그 커뮤니티에 질문을 올렸다.
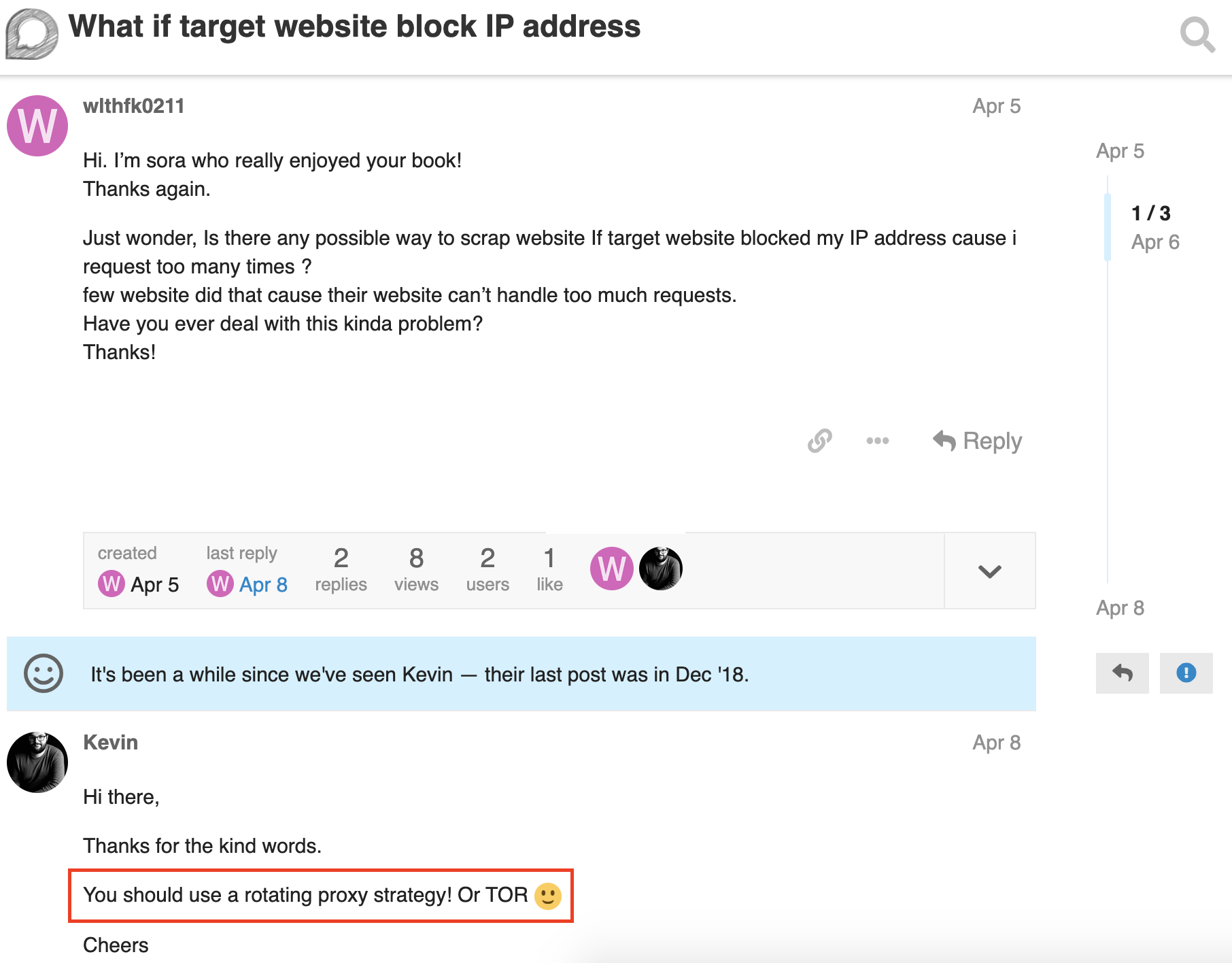
그리고 답변에는 내가 원하던 개념이 적혀있었고, 알고보니 이미 ebook에도 적혀있었다!!!

‘내 ip주소를 숨길 수 있고’ 라는 부분을 보면서 ‘이거다!!!!!!!’ 라는 생각이 들었고, 이걸 퇴근길 지하철 안에서 보고있었는데
정말 집에 가자마자 실행해볼 생각으로 집에 달려갔던 기억이 있다 ㅎㅎㅎㅎㅎㅎ 너무 신났었다
해결 과정
사실 저 책에 Tor브라우저를 어떻게 사용해야하는지에 대한 코드가 나와있지는 않다.
모든 책이 그렇다. 어떻게 모든 코드를 다 넣을 수 있을까? 그건 말이 안된다.
나는 이렇게 검색을 하는 과정이 어떤 문제의 ‘실마리’ 혹은 ‘힌트’ 만이라도 알게되는데에 의미가 있다고 생각한다.
처음에는 검색을 어떻게 해야할지도 몰랐는데
프록시라는걸 알게되고, 토르브라우저라는것을 알게되니까, 검색하는 내용이 확 달라지기 시작했다.
토르브라우저 설정방법, ip가 실제로 변경되었는지 확인하는 작업 등등 검색을 통해서 하나하나 해결해가기 시작했다.
물론, 개발이 이후로 쭉쭉쭉 물 흐르듯이 진행된건 아니다.
당연히 에러도 많았고, 그 와중에 안되는 부분도 많았다.
그렇지만 어쨌거나 메이저 개념에 대한 문제의 핵심만 알았다면 조각조각을 수정하는것은 어렵지 않다.
이렇게 해결!
복기
이때 당시의 이 문제는 내 개발인생의 가장 난이도 있는 수준의 챌린지였다.
(이후에 어떤 문제들이 펼쳐질지도 모르고… 훨씬 더 난이도 있는 문제들이 많았다^^..)
이때 얻었던 가장 큰 3가지는
- 문제에 대한 핵심 개념만 잡으면 그 다음은 부품을 수리하는 과정이다. 라는 사실을 깨달은점
- 문제의 핵심 개념을 잡기 위해서는 책, 강연, 온/오프라인 강의, 검색 등 그 어떤 수단을 이용하던지 잡을때까지 찾는다.
- 하니까 된다. 라는 자신감
이었다.
물론, 개발지식적인 면에서도 얻은점이 많았지만 앞으로도 계속해서 지식들은 쌓일거고
어찌보면 지식이 쌓인다는것은 개발자 입장에서 너무나 당연한 일이라 그건 그냥 얻을 수 있는 기본값으로 생각한다.
프록시 우회 크롤러 개발을 하는 동안 ‘뭐든 하면 되겠다’는 생각을 많이 하게 됐다.
그리고 10년동안 해결하지 못했다는 다음 문제를 해결하러 갔다….
